Yet again, another fast written and unedited article. I don’t mean to make light of the massive math/statistics/engineering achievements behind what I am going to run over in the following text.
We know that the internet is three things:
1. A number of computers “servers” that are connected to each other and connected to households - via phone lines, fiber or whatever.
2. A system of asking for websites from the servers with easy to remember names “www.spiegel.de”.
3. A method of structure information that is compelling, a combination of text, videos, clickable things and whatever else you find on a website
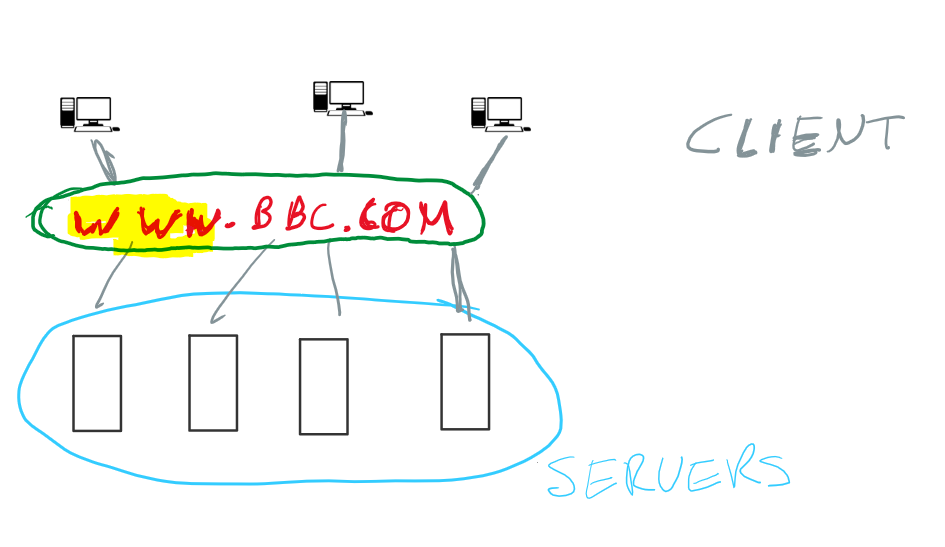
However, there is more. Not only can you get to a website by knowing it’s address, websites are also linked. On website can refer to another website and make it easy to navigate there using hyperlinks.
Links are not unique to html, the language of the internet that this website is written in, they were already used in Gopher, arguably even mentioned as a concept in “As We May Think”, the famous Vannevar Bush essay. They turn out to be extremely important.
What problem does a search engine solve
We now know, that there are only two ways of accessing content on the internet: via a link or if you know the address directly.
Initially the web was more about “discovery” than “search”. Discovery means that I have less of a target that I look for and more get an understanding of what is there. Often this is “categories”. A current day example of a strong discovery product is Instagram or Pocket.
This is the time when lists are the dominant way to explore the internet. Makes sense as you know that you are interested in cooking or woodwork but don’t have a specific query in mind so a list of the best woodwork sites helps you well. You can think of a portal as a more dynamic form of a list.
Now, as the web matures users start to know that there is probably content out there, the problem becomes finding it. Compare this: looking up “woodwork” in a list of hobbies fairly fast and pleasurable for a human, finding an article on “the best courses on woodwork in Oregon” is no longer something works in a list. Should I look at the list for courses, or the list for Oregon or the list for woodwork?
So, what is search? Initially, search is a query, i.e. what you are looking for. Then it is a set of possible answers.
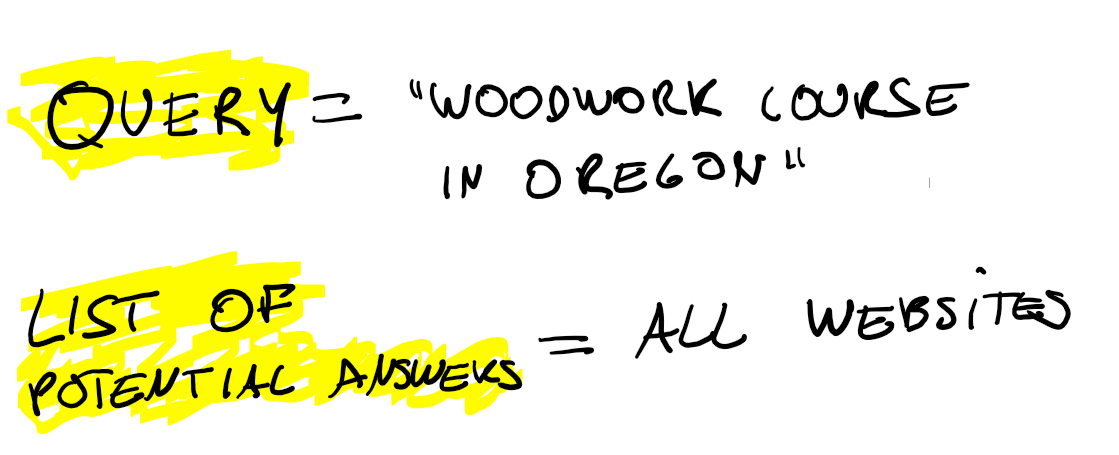
Given this, the exercise becomes how can we sort the potential answers in a way that they match what the users want. One extreme solution you could think of would be to serve the websites randomly and just take not of which one the users clicks. Than, next time somebody search for the same website rank this website highest.
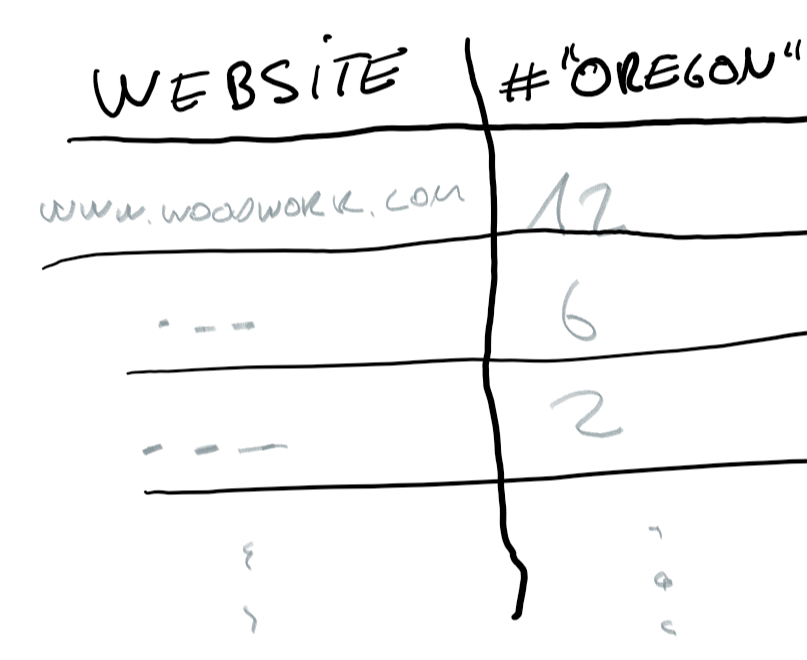
A better version would be, that you send around a robot that counts city words on websites. So when the robot is done crawling through the whole internet a list comes out like this the picture on the right.
Basically a table that contains a list of how often “oregon” appears on a certain website. Now you search algorithm might breaks apart the input, notices that the user ask for something containing oregon and generate a ranking of websites based on this algorithm:

Now, there is a certain amount of algorithmic stuff you can do on a website. For example, you can give a weight to words that are in a headline or you can try to discount words that sound like a list of cities and elements like this. There is massive complexity in building up the database we mentioned earlier. Because that means extreme amounts of crawling information and synthesising it.
This type of information relies entirely what is on the site, in SEO circles stuff that relates to what happens on the website is therefore called “on-site”.
However, an external and therefore potentially more objective variable to output the liklihood that a given website matches the query of user is the number of links pointing to a website.
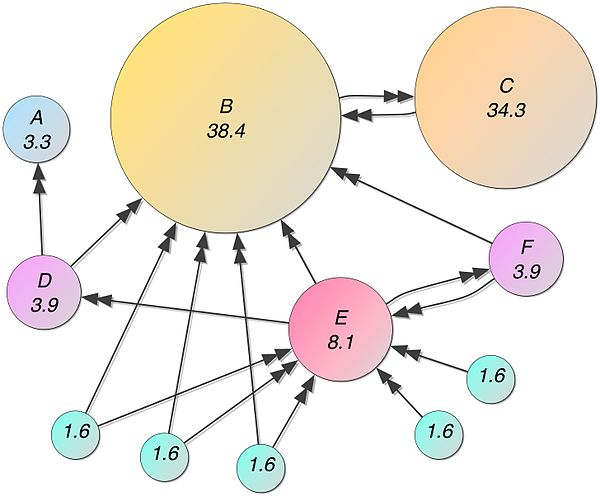
The math (“eigenvector” behind this I cannot explain, yet intuitively the importance of a site is increased by the number of sites point to it. That requires you to have a complete map of the internet.

Now, in access of the on-site and the of-site criteria, a third input for the ranking of potential results could be “context” a made up example could be that if people google “fish” on Saturday night, this is more likely to be a search for a fish restaurant, whereas if it is googled in the late morning, this indicates a query for biological content - in this example the context is the time at which the query is made.
Google is known to use other factors such as “is a website optimised for mobile devices”. This is essentially a political decision by Google to use a factor like this as an input.
In general, the SEO industry is full of a lot of advise on the google algorithm. Nobody really knows what is considered heavy - naturally because it is not in the interest of google to promote the website that follows most specifically to their algorithm but rather give rough hints on what matters and what does not.
Matt Cutts used to be the speaker of Google search, it always reminded me of central bank announcement. Not fully confirming rate increases in the future but pointing towards a direction pretty specifically. In generally, SEO is quite straightforward: guess what google cares about and implement that. Be it getting links from reputable third parties, content from writers or a mobile ready website.
How google will get a problem
This relates to google search, less from a business (=profitability) perspective more from a user perspective.
“Search” is no longer a process of discovery. Search is extremely profitable as a way of advertisement because it expresses intent, you are searching something so you want something. If that notion of expressing something through a means of searching goes away, than a problem arises.
My guess would be that this happens because specific types of content get aggregated. For example, capterra takes over comparison of software features, pocket and medium take over content and amazon takes over product search.
“Relevancy definition changes” to me, this is the most interesting. Relevancy relies on content and links. If this where to change, for example because a micropayment of some sort is established, the paradigm becomes worth less.
“Means of input changes” if search moves to voice, this is not a probem since voice can be made text quite easily. But if search is broken up into particular contexts, as written above this does become a challenge.